A Taxonomy of Security Issues
Mark S. Miller
January 25, 2021
for understanding language-based security and modularity
Increasingly, programmers build secure systems using secure programming languages. What do secure languages contribute to overall system security? What is the relationship between building secure systems and building modular composable systems? Is language-based security competitive with, or complementary to, OS-based security? If we cannot stop secrets from leaking outward onto side channels like Meltdown and Spectre, as seems plausible, what forms of security become impossible?“Security” is an overly broad umbrella term, leading to much confusion about these matters. We need to make some distinctions. This essay presents a taxonomy of issues and approaches. It then explains both what forms of security are possible when using which technologies and what forms are necessary for large-scale software engineering. We illustrate our points with issues from the design of JavaScript, and of SES, the object-capability form of JavaScript.The taxonomy introduced in this first document is general, but we start with programming languages. Later documents will build on this framework to explain security and modularity issues in operating systems, distributed systems, and blockchain-based decentralized systems; as well as the coupling between them.
Integrity, Availability, Confidentiality
We start with the traditional distinction between integrity, availability, and confidentiality.
Integrity, also known as Safety or Consistency: No “bad” things happen. Bob stealing Alice’s money is an integrity violation. Integrity rests on access control determining what agents can cause what effects.
Availability, also known as Liveness or Progress: “Good” things continue to happen. Bob preventing Alice from spending her money as she wants is an availability violation, also known as a denial of service. The most common threats to availability are resource exhaustion attacks, such as Bob allocating memory that Alice needs to proceed.
Confidentiality, also known as Information Hiding or Secrecy: No one can infer information they are not supposed to know. Bob figuring out Alice’s secret balance is a confidentiality violation. The most pernicious threats to confidentiality are side channels like Meltdown and Spectre, where Bob infers Alice’s secrets from timing differences.
Integrity
An important principle followed by memory-safe languages and many operating systems is integrity should never depend on confidentiality. Put another way, integrity should never be threatened by a loss of confidentiality. For example, a JavaScript object reference is unforgeable even by JavaScript code that knows how objects are laid out in memory. Public blockchains like Ethereum dramatically demonstrate integrity’s independence from confidentiality. All Ethereum computation is public. Ethereum programs cannot keep secrets. Nevertheless, they deliver strong integrity and availability under hostile conditions. The discovery of Meltdown and Spectre did little to weaken Ethereum’s security. Integrity is the bridge between “normal” software engineering and software “security”. The central problem of both is robust composition. When we compose separately written programs so they can cooperate, they may instead destructively interfere with each other. To gain the benefits of composition while minimizing potential interference, we invent modularity and abstraction mechanisms. In JavaScript, all of these defend integrity: memory safety, lexical scoping, closure encapsulation, function and method invocation, private instance fields, object freezing, module separation, membrane separation, encapsulation-preserving reflection, and message passing between event loops. Most of these are elements of normal programming. The integrity of their separated components helps programmers reason about their code in a modular manner. Secure programming is essentially normal programming practice in which modularity considerations are taken to an extreme. Software engineering defends integrity against accidental interference, bugs. Software security defends integrity against intentional interference, attacks. It is no coincidence that mechanisms effective against one are effective against the other. Good modularity mechanisms are effective against interference, whether intentional or not.
Nested Boundaries and Channels
Operating system security is based on process boundaries separating address spaces. This rests on simple hardware mechanisms—MMUs mapping virtual to physical memory addresses—that have withstood the test of time. Despite a long history of attacks on operating systems, hardly any have been against this basic separation mechanism. By contrast, language-based security builds boundaries within a process. History shows these finer-grain boundaries are much harder to get right. Meltdown and Spectre amplify this difference. These specific side channels are leakier within a process than between processes. A common position is that because process boundaries are so solid, we don’t need finer-grain boundaries within a process. This is like saying that because your house’s walls are a defensible perimeter, you do not need skin. And because you have skin, you do not need cell membranes.
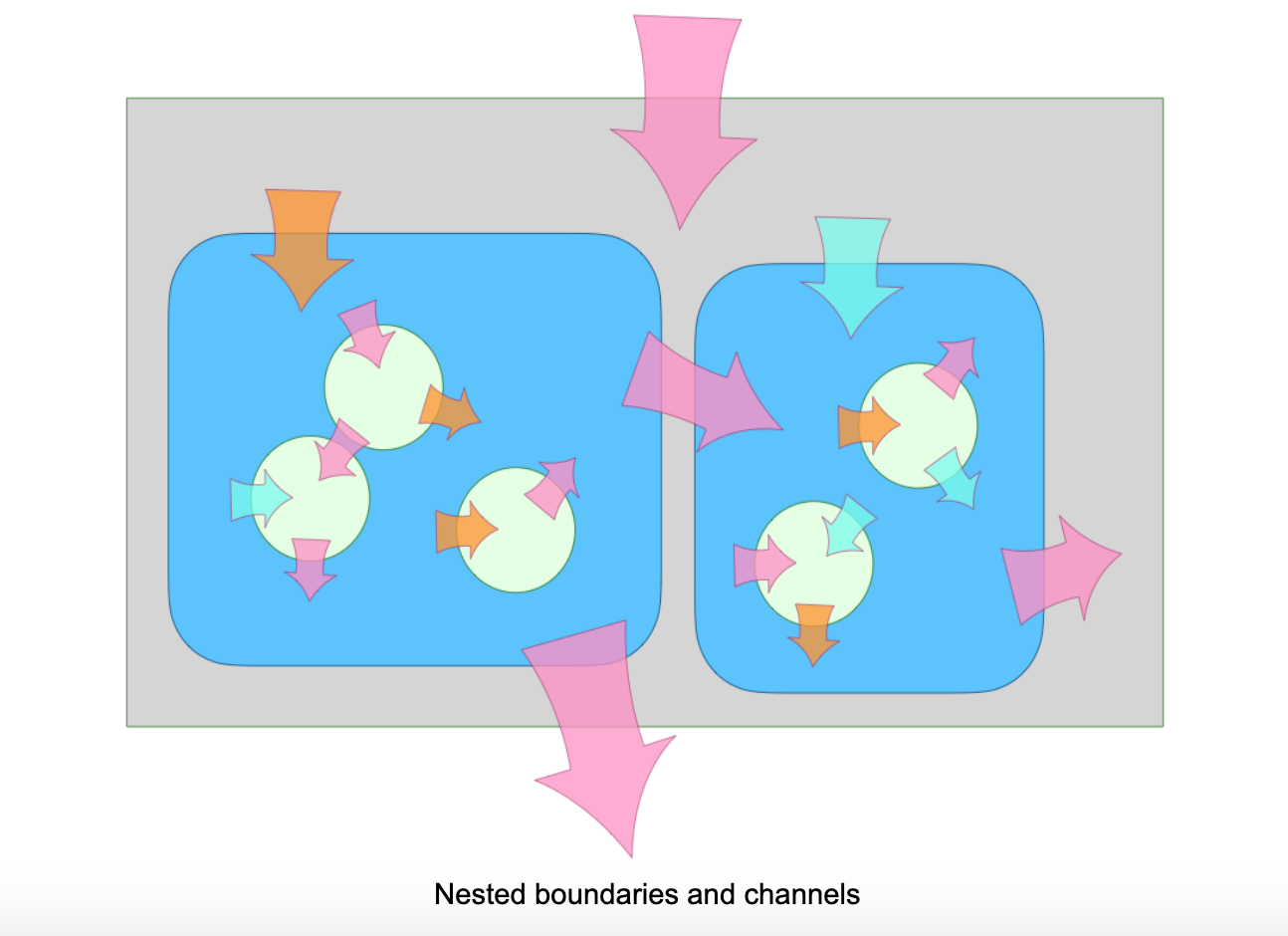
taxonomy1
Of course, biology does not work this way. Instead, we ourselves are composed of systems at multiple nested granularities, such as organelles, cells, organs, and organisms. Likewise, we ourselves compose software systems at multiple nested granularities, such as closures, classes, modules, packages, and workers. In both biological and software systems, to gain the benefits of composition at each granularity, defensible boundaries reduce potential interference. Simultaneously defending boundaries at multiple scales produces a multiplicative reduction in risk. Different boundaries have different characteristics, but they also have many abstract organizational principles in common. One of those principles is that boundaries are semi-permeable, allowing some things to pass while blocking others. The boundaries at different granularities differ in both what they can block, and what their channels can carry across them. As a result, they differ in both what kinds of composition they can support and what kinds of interference they can prevent. Let’s break this down, again by integrity, availability, and confidentiality. Out of the box, JavaScript has flaws that weaken fine-grain integrity, such as non-static scoping and potential prototype poisoning. It also has antidotes to these flaws, such as strict mode and Object.freeze(). These antidote features support SES (Secure EcmaScript), an object-capability (ocap) form of JavaScript. In SES, integrity is pervasive, from fine grain memory safety and closure encapsulation to large grain asynchronous messages between processes on distant machines. The boundaries at all granularities can flawlessly defend integrity by blocking effects. By themselves, fine grain boundaries cannot protect confidentiality. They cannot block the leakage of information over timing channels—by measuring the time that different operations take. Fine grain boundaries are totally unable to defend availability. At fine grain levels, denial of service is as trivial as an infinite loop. To summarize:
Integrity can be strong at all granularities.
As for availability, at all granularities within one thread of control, anything can trivially block everything. Thus, we cannot defend availability at all. The minimal defensible unit for availability is the shared-nothing concurrent thread of control, such as a process, worker, or vat. Blocking one thread of control need not prevent the progress of others.
Confidentiality, it turns out, is more interesting…
Overt, Side, and Covert Channels
For language-based security, the interacting agents are programs whose behaviors are based on
the specified semantics of the language they are written in
the actual implementations of the language they are written in
This duality gives us our first distinction between kinds of channels for conveying information or effects. For each channel below, we have sender object Sam and receiver object Rachel.
An overt channel is one that the language specification says will convey information. Sam assigning
x = 1communicates1to Rachel who can readx. In an ocap language, overt causality is only carried on shared lexical variables and on object references, so subgraph isolation also isolates overt communications channels. There are two kinds of overt channels, divided by the intentions of the parties involved:An intentional channel conveys the information it is legitimately supposed to convey. Its purpose is to advance computation to its intended outcome.
Subliminal and steganographic channels encode into overtly transmitted information hidden information for purposes outside that transmission’s “legitimate” purpose.
A non-overt channel relies on unspecified behaviors of actual implementations. Languages generally do not specify the duration of various operations. The most common non-overt channels, including Meltdown and Spectre, rely on Rachel measuring the durations of various operations. There are two kinds of non-overt channels, again divided by intention:
A side channel is one where Sam, the source, does not intend to leak information to Rachel. For example, if Sam is an encryption algorithm encapsulating an encryption key, Rachel might ask Sam to encrypt text chosen by Rachel to amplify differences in secret key bits into timing differences she can measure.
A covert channel is one where Sam intends to leak information to Rachel. Sam may purposely vary the duration of internal operations in order to signal Rachel.
Of these, only intentional channels aid composition. The other channels are risks of composition that we wish to mitigate.Among non-overt channels, it is much easier to defend against side channels, where Sam accidentally leaks, than defend against covert channels, where Sam is actively trying to signal. But it is no easier to be invulnerable against side channels than covert channels.This seems paradoxical. By “defend” we mean imperfectly. By “invulnerable” we mean perfectly. Any misbehavior that Sam may engage in intentionally, he might engage in accidentally. The probability distributions differ, but not the line between possible and impossible. Good protection mechanisms prevent leakage, whether intentional or not. A correct program relies only on the specified semantics of its programming language. Although a correct Sam program may leak information over non-overt channels, a correct Sam program only acts on information it receives over overt channels. We can thus ignore non-overt channels and still reason soundly about Sam’s integrity. Much formal reasoning about confidentiality of programs starts by assuming away the existence of non-overt channels. Such reasoning is unsound. It will miss how Sam’s secrets leak due to timing variations of an operation’s implementation. But neither is it practical to reason about implementations, as each new implementation of the language would require us to redo that reasoning from scratch. Meltdown and Spectre show that this burden extends to each new implementation of a machine’s instruction set architecture! Without reasoning about specific implementations, how may we soundly defend confidentiality? By definition, non-overt channels are found in the gap between the language’s specified semantics and actual implementations. A perfectly deterministic language would close this gap—it would fully specify all observable effects of running a program on any correct implementation of the language. However, such programs could not interact with the outside world, even to read the clock, since the time values must be predetermined by the language’s semantics.We avoid this I/O problem in languages that are fully virtualizable in the sense discovered by processor architects. In a fully virtualizable language, there is a strict separation between the user-mode purely computational language vs the system-mode (host) objects that provide I/O access to the external world. The JavaScript language provides purely computational objects such as arrays and maps, while each JavaScript host provides host objects like document or XMLHttpRequest for I/O to the user or network. SES leverages JavaScript’s almost perfect conformance to this model and closes the remaining gaps: Date.now() and Math.random(). Take the SES Challenge.

Screen-Shot-2021-05-21-at-1.46.48-PM
Given an extremely loud side channel, write JavaScript code to steal the secret. The purely computational SES language does not have a fully deterministic spec because the purely computational elements of JavaScript do not. But the remaining forms of underspecification leak only relatively static information, such as what version of what JavaScript engine is being run. It does not leak information that changes dynamically while a program runs, and thus does not provide non-overt channels between SES programs. Virtual host objects provide all access to dynamic non-determinism, including all access to the outside world. These virtual host objects can be denied or further virtualized as one subsystem creates another. If Rachel is a subsystem that has been denied all sources of dynamic non-determinism, then no matter how leaky Sam is, whether intentionally or not, Rachel cannot read the non-overt signals Sam is sending.
Least Authority Linkage
Most applications need to interact with the world outside of themselves, including users and networks. Such applications cannot practically be denied timing channels. However, many library packages are purely computational, such as parsers, formatters, static analyzers, linear algebra packages, constraint solving libraries, and many more. All of these are given all their input up front, process it to compute an answer, return that answer, and stop. Such library packages never mention Date.now or XMLHttpRequest. They do not import other libraries that would give them access to the outside world. Automated analysis tools can see that these libraries do not need any such access. Under SES, such a transformational library package runs in a compartment that does not provide access to any means of measuring duration. Once confined to such a compartment, that library package cannot read timing-based non-overt channels—including Meltdown and Spectre.
Supply-chain Vulnerabilities
Many security discussions use the terms “trusted code” and “untrusted code”, as if there is a clear distinction. There is not. Although you trust that the code you wrote yesterday was not written maliciously, you should not trust it not to act maliciously. It may have a flaw enabling an attacker to subvert it. That’s why we write tests, do code reviews, and engage in all the modularity practices described above. We also all use massive amounts of code written by others that we cannot possibly examine adequately enough to fully trust. NPM estimates that 97% of the average JavaScript application’s code is from linked-in third party libraries. Only 3% is written specifically for that application. Attacks have been perpetrated by malicious upgrades to widely used libraries. Of the various software engineering granularities, the package is the one most relevant to JavaScript supply-chain vulnerabilities, as it is the clearest unit of separate authorship and revision. Different packages are distrusted differently, to different degrees and in different ways. In theory we could protect packages from each other by putting each into its own process, and do all inter-package linkage via inter-process communication. But how realistic is that? For anyone who has done any programming, the answer is obvious. By contrast, experiments at Google, Salesforce, Node, MetaMask, and Agoric show that many existing JavaScript packages, not written to run under SES, nevertheless do run compatibly under SES, realistically limiting the damage each package might do to the others.
Welcoming and supporting intentional cooperation
Not all communication between parties is nefarious. We must not think only of walls to keep dangerous behaviors out and confidential secrets in, but also of ways for agents which wish to cooperate to do so. Failure to do so in our initial designs will result in communication channels being added later in an ad-hoc fashion with more authority revealed than intended. Without architectural principles for rich cooperation across these boundaries, users simply take sledgehammers to the walls, knocking out wide gaps for the sake of convenience.A better choice is to plan cooperation mechanisms up front. Language-based ocap security, built on simple scoping and argument passing, provides a familiar and useful way for programs to cooperate intentionally. In any memory-safe object language, arguments are already unforgeable references to objects. An argument designates an object in order to parameterize the meaning of the request, and provides the receiving object permission to invoke the argument object. Locally, both synchronous calls and asynchronous message passing provide an excellent and intuitive pathway for sharing authority. Messages between objects remain an effective composition mechanism across large scale boundaries as well. In a future paper in this series, we explain the cryptographic CapTP protocols for conveying these same asynchronous messages safely between objects on mutually suspicious machines.We get from memory-safe objects to ocaps mostly by removing support for already recognized bad practices, leaving support for good practices intact. The elements that SES removes from JavaScript—so-called “sloppy” (non-strict) mode which violates lexical scoping, the mutability of implicitly shared objects which enables prototype poisoning, and linkage by mutating global state—are already avoided by code following recognized best practices. This is why so much existing JS code runs compatibly under SES.
Discussion and Next Steps
Herbert Simon’s 1962 Architecture of Complexity explains that many complex systems have an almost hierarchical nature. They consist of deeply nested subsystems, with some imperfect degree of separation between subsystems at each level of nesting. To understand such systems, we must understand two things. First, how these subsystems are somewhat insulated from each other by boundary mechanisms. Second, how they influence each other by channels across these boundaries.The separation of these subsystems enables their separate evolution and their compositions into systems serving larger purposes. The influences they have on each other can either serve or interfere with these larger purposes. We use this framework to understand natural systems we observe, as well as to engineer systems we construct. When analyzing software systems, at each level of composition we can examine these boundaries and channels in terms of integrity, availability, and confidentiality. These terms come from software security; the same concepts reappear in software engineering with different names: safety, liveness, and information hiding. This terminological difference has obscured the alignment of their concerns. We have explained these concerns in a unified manner. These issues reappear at each scale, but with different strengths and weaknesses at different scales. In this first document we zoomed in through finer grain perspectives to understand language-based security and modularity in the small. We explained how these concerns have affected the design of both the JavaScript language as a whole, and SES, the object-capability form of JavaScript.With this taxonomy to build on, upcoming documents will zoom back out, to cover processes communicating within an operating system, single machines communicating with each other by cryptographic protocols, and finally blockchains communicating with single machines and each other over inter-chain protocols. We hope you’ll join us for these explorations of language-based security and modularity in the large.